
I’ve never been to a hackathon, even though I’ve heard a lot about them. However the HSLU (Hochschule Luzern) together with Stair arranged a Hackathon and a friend of mine invited me to join, so I accepted.
This is a retrospective on that experience.
The Topic
The topic was “Social Media”. Specifically we got the goal to write an application that addresses one or multiple of the problems that come with using social media:
- Data protection
- Mental health
- False information
- Cyberbullying
- Addiction
Choosing what specifically we’d do was a lot harder than we first expected. We had some ideas but eventually settled on using AI to analyze post/comments for emotions and general mood. We wanted to cover the mental health and cyberbullying problems with it.
Finding a way to actually do this was quite a bit harder than first expected. We wanted to use Twitter/X initially, however due to recent API changes this ended up not being possible. We had the same problem of a missing useful API with Reddit too, so we ended up deciding to use YouTube.
You might now say that YouTube isn’t what you’d usually think of as a social network, and arguably you’d be right. It doesn’t have posts (we will be ignoring the community feed as it’s only rarely actually used), but it does have comments. Which is all we require.
The Project
So what is Comment Care actually, and what does it do? I think it’s easier to show than to tell, so let’s do that.
First we have the start page, here you are able to paste a YouTube link and continue.

It then loads for a while, usually around 20 seconds. The reason for such a long loading time is mainly that we use AI models to analyze the text. It also only runs on CPU (mainly because we had to make sure that it truly runs eveywhere without any potential issues).
Once it has finished loading though you will be able to see the analytics we have generated. Note that the API only provides us 20 comments, so anything more than that we can’t analyze as we are unable to aquire the data for that (and it would probably take too long to precess anyways…).
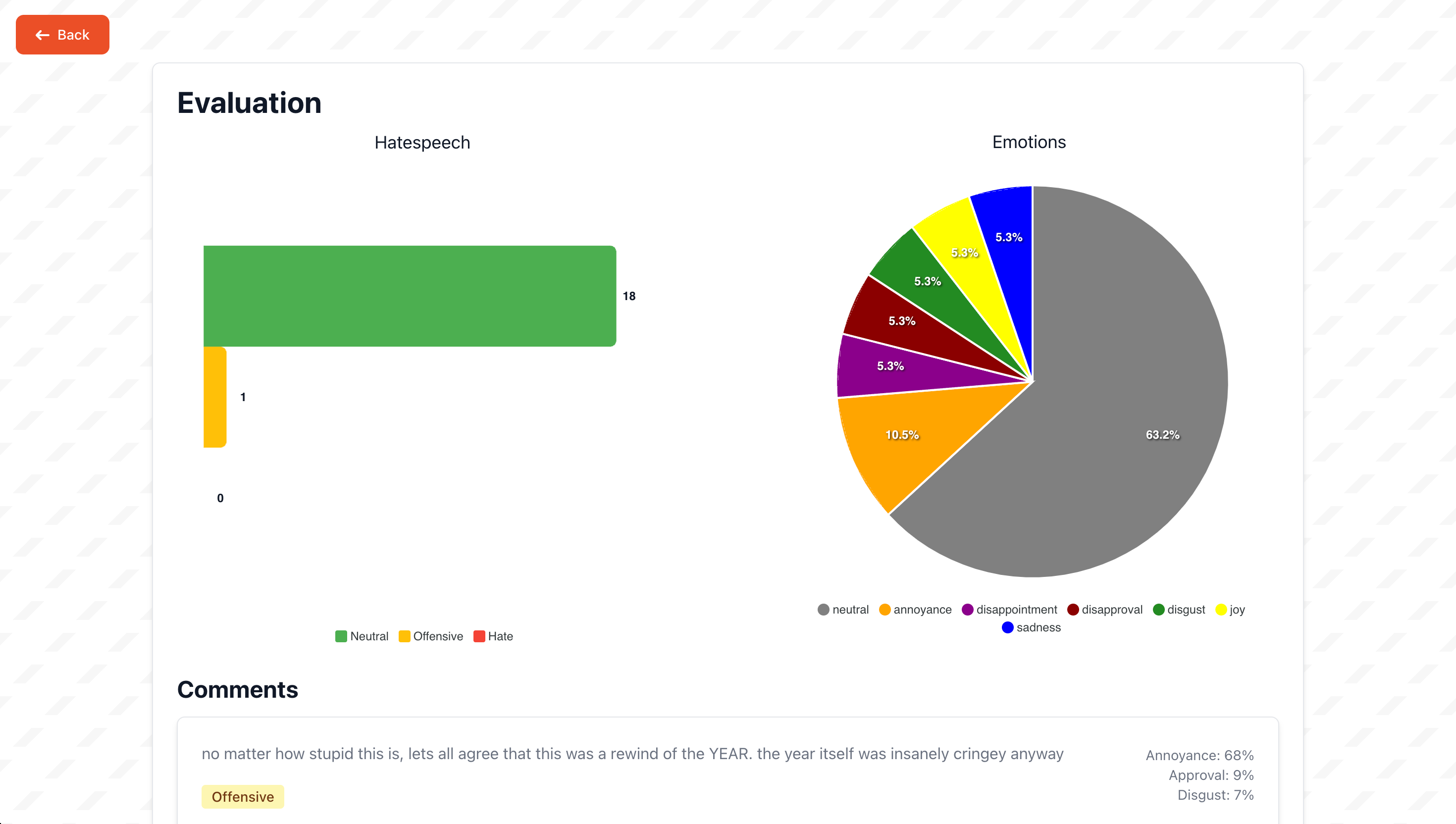
At the top you can see two graphs. One graph about the number of comments that contain hatespeech, and a second one showing various emotions that are present in the comments.
Finally you see all the comments that have been analyzed down below in a list, as well as the data we got from them.
Technical Specs
The frontend has been written in Svelte and compiled to a single static html page. We used Flowbite as the component library.
The backend meanwhile was made in python and hosts the AI models as well as the access to the YouTube API.
We opted to turn the entire project into a docker container, using nginx as a reverse proxy to pass the requests to either the backend or the frontend (which at this point is just static files).
What we learned for next time
A bit of time has passed at the point of writing this and it’s given me time to reflect on what went wrong and what we could have done a lot better.
Spend more time coming up with ideas
The topic that was given to us was very open. This is good in itself, but it also means that you aren’t given a lot of guidance on what projects may be a good idea.
We focused on this “analyze someones emotions of posts and use that to figure out how they are doing"idea that we had quite early on. In my opinion the biggest mistake here was not changing out opinion after realizing that all social media platforms (or at least the ones we were familiar with) shut down their APIs recently (Reddit and Twitter), making a project like this almost impossible.
What we should have done was to change our mind, forget about this idea, and make something completely different.
Make sure you can’t misunderstand the use of the application
Another issue was that we have underestimated the size of the AI runtime (incl. pytorch). Our docker image ended up reaching around 12GB at one point (although we were able to get that down somewhat).
This ultimately resulted in the image taking a long long time to download (especially on a very busy wifi as we had it during the event).
These runtimes also caused a long startup time, which means that the backend would take around half a minute longer to start up than the frontend. Ultimately this lead to one of the judges of the project thinking that the software was buggy/unreliable, as it wasn’t working the first time they tried it as it wasn’t finished with starting up yet.
This could have been fixed by e.g. checking if the API was operational first. But to be honest I think the main problem with this here was just that we tried to do everything in one container and not use any cloud APIs.
If we just used a Cloud API this application wouldn’t even have needed deployment (or any deployment more than Gitlab pages at least).
We didn’t win, which seeing the problems we had is not really that unexpected. We have definitely learned a lot though from this experience, and had a lot of fun with it too. So next time we should definitely end up doing much better and hopefully have a much better shot at winning :)
Special thanks to my friend Loris who invited me to join him at the event. You can find his website here: janner.dev.