Stash is a featureful tag based library web-application to organise your media into easily browsable and searchable collections, that you can access from anywhere.
Backstory
A long, long time ago (like a year or two) I used to use Raindrop to manage a lot of media files because it has good tagging functionality, but I ran into limitations, a lack of polish on features I cared about, a 100mb per file limit, and a general slowness of the whole application (to be fair, I don’t think it was designed for massive media collections and more for collecting links, but the point still stands). Unfortunately, I couldn’t find another alternative that ticked all my boxes.
Of course, I did what any “sensible” person would do and created my own solution, tailored to my personal needs. Little did I know that this “little weekend project” would end up expanding far beyond a minimum viable product.
Please note, that this project is open source, however I do not (yet) recommend you use it. Because part of my initial idea for the project was for it to just be a “weekend project”, things are still not implemented in ways that I am fully happy with. Some things are still hardcoded (so not configurable unless you count making a fork as “configuration”), and the project is not setup for non-breaking-changes.
How it works
The application is a SvelteKit project that get’s deployed as a Docker Container. I used to use go as the backend, however I decided to stop using that as I have ran into a few issues, and the code became a pain to maintain.
For the Database I use PostgreSQL (run as a seperate container), as it has a lot of features and can easily be hosted locally. I access it though Prisma. Generally this works quite well but I would probably choose a non-sql solution in the future because the media and tag queries are starting to get uncomfortably large and convoluted.
Oh, and there is also a Redis database for logging database queries, but that might not stay here for very long anymore as the reasons I needed this verbose debugging have mostly been fixed.
While theoretically Stash can store any file, only images, and videos have full support. There even is a special collection for stories in markdown with a (basic) only reader and automatic import and formatting support for select platforms.
Tag System
The core of Stash is it’s tag system. While it is intentionally kept simple, it allows a media object to be assigned to multiple tags. Additionally tags can have more detailed sub-tags. This way you might have a tag called “pets” and then sub-tags like “cat” or “dog”. When viewing the tags you can then decide if you want to see both the parent and child tag items, or just the parent tag items.
In addition to a simple label for the tag, a tag can also have an icon and description assigned to them. Although still not fully polished, you can now (May 2025) also make tags more powerful by allowing child-tags to be non-hierarchical, which is fancy speak for allowing you to tag a tag with another tag (try to say that 10 times fast). You can then opt in to show these “linked” tags with the traverse option from the command pallete.
AI Tagging
When you upload a new media file (currently only support for images is implmented, but support for videos is planned in the future), Stash will automatically run it against a number of AI-enabled tags. While this might sound complicated but it’s actually quite simple.
The tags that the user has already defines can have a description added to them, which is just plain text describing the tag. The worker will then in the background after the import go and send the image to an LLM with a long prompt that includes all tags which have descriptions, along with the description itself. The LLM will then return a list of tags that it thinks are relevant for the image as a structured JSON file.
Using a description system like this has multiple benefits. First it means that not all tags are automatically used by the AI. I’ve noticed that the models are still quite stupid and are often wrong, so you can tweak the tags that are used by the AI. Second it means you can explain what you mean by that tag to the AI, as the name itself can and will be interpreted in multiple different ways, none of which are what you actually intended.
However this is not a perfect world and there are some issues here. Most importantly is, that the selection of a good model to use for this use case is much harder than I originally expected. First off the number of models (that I can easily run through OpenRouter), that both have support for image input i as well as tool calling for the structured output, is rather limited. In addition the models that do fill these requirements are either really stupid (they need to be quite “smart” for this tagging process to be actually helpful), or are astronomically expensive. Keep in mind that I am a working student so I can neither justify spending a lot of money on API usage, or buying a new fancy NPU or GPU. I might cover a solution to this in the future… as soon as I can come up with one… so stay tuned!
Adding and Importing Media
A nice way to organise your media is only useful if you have the ability to add media to Stash. To do this you can use the import popup, which looks like this:
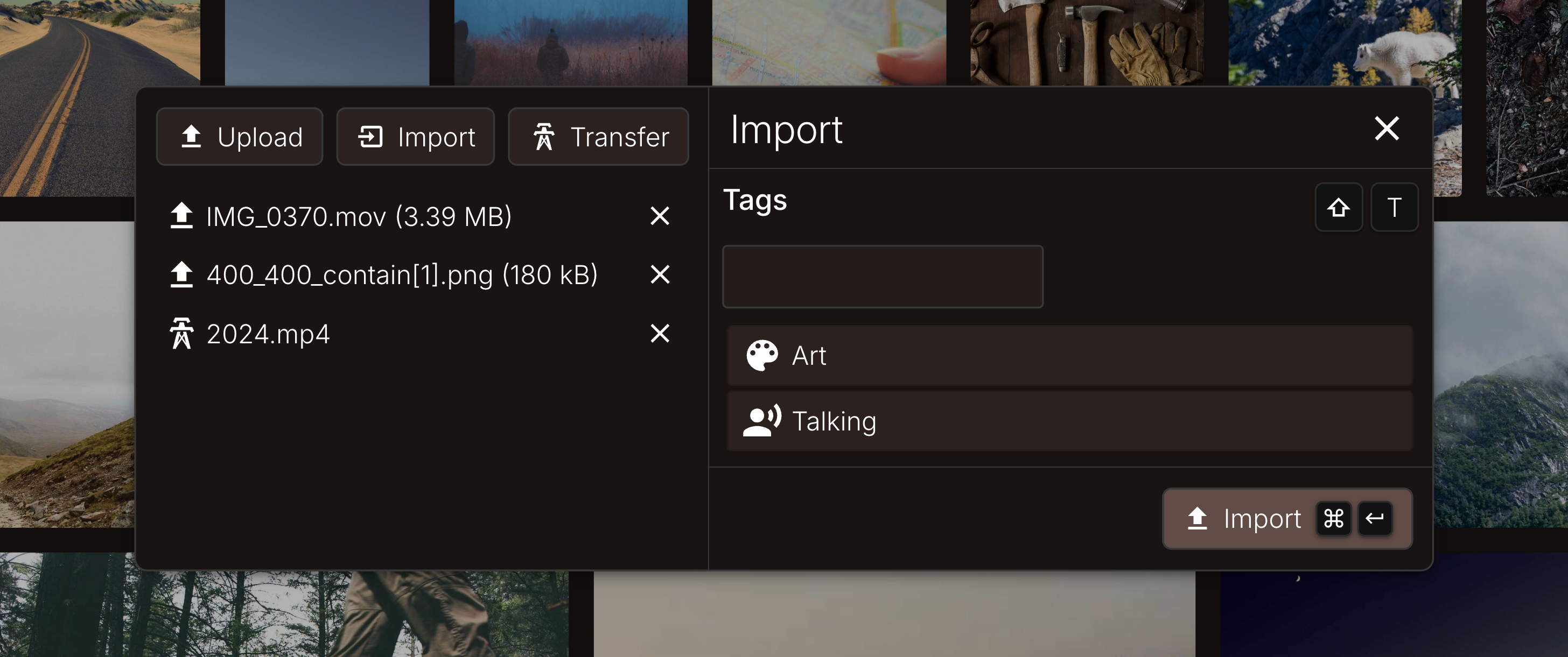
Stash can import media files from a number of sources in order to adapt to the specific kind of media you want to import. You can upload media from your local machine directly from the web interface, so far nothing special.
However what if your media files are big? Like really big? For this direct uploads over the browser might not be the best choice as they can take forever and, at least for this implementation, the bigger the files get the more likely it is that the upload will fail (if you are bored, feel free to make some MRs to fix this). So to cover this use case you can import files from a local directory. Local in those case meaning directly on the server where Stash is running, by exposing that directory though docker binds. This allows you to import huge files instantly (or slightly slower of the folders are on different file-systems).
Thirdly and lastly (for now), you can import files directly from the Transmission torrent client. Stash achieves this by using the Transmission API to move and rename the files to their final resting place. This allows you to continue seeding the media files, even after importing and tagging them, and shows some of the power and control that you can only get with a self-hosted and custom-built integrated solution.
Future Plans
I plan on continuing to develop this application, as I am using it myself regularly and find it extremely useful for my purpose. It is not even close to being complete though and has already used a lot of my time though, so don’t expect it to be finished anytime soon… or probably ever. Nevertheless here are some of the features that I still plan to add:
- Importer from various web sources
Probably using yt-dlp, as well as some auto-import scripts for sites like Patreon or Twitter - Automatic media optimisation
A lot of media files aren’t well optimised, even without loosing any quality a lot of storage space can be saved - Final goal: Make everything customizable (nothing hardcoded)
This would finally allow other people to use the software too, a lot of work is needed though to get the application to this point and at the moment it is unclear for me if I want to putin the effort for (probably) 0 actual users